Azure Synapse Analytics
Azure Synapse Analytics
Introduction
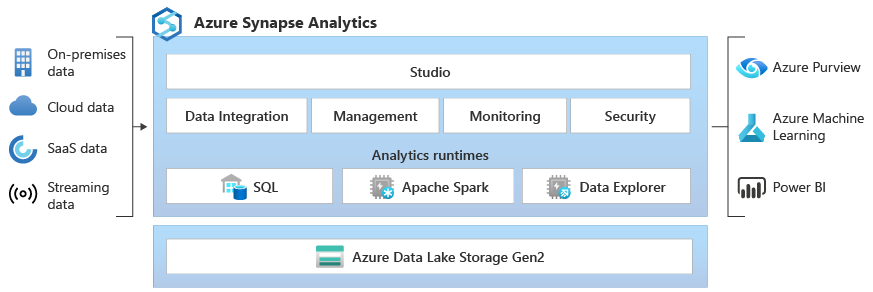
Azure Synapse Analytics is a unified analytics platform that brings together data integration, big data processing, and data warehousing in a single environment. It combines the capabilities of:
- Azure Data Factory (ADF) → For building data pipelines and orchestrating workflows.
- Azure Data Lake Storage (ADLS) → For storing raw and processed data efficiently.
- Synapse Spark Pool → For big data processing (like Databricks, but with some limitations).
- Dedicated SQL Pool → For structured data warehousing, with support for distributions to optimize performance.
With Synapse, you can ingest, transform, store, and analyze data using SQL, Spark, and data pipelines—all within one integrated platform.
Key Components of Azure Synapse Analytics
1. Synapse Pipelines (Similar to ADF)
Synapse Pipelines enable data movement, transformation, and orchestration across multiple sources. They allow users to build ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) workflows to process data at scale.
- Supports multiple data sources but has fewer connectors than ADF.
- Does not support on-premises integration, unlike ADF, which has an On-Premises Data Gateway.
- Provides built-in activities for data ingestion, transformation, and scheduling.
💡 Think of this as ADF inside Synapse, but with some limitations.